数据科学中的常见的6种概率漫衍(Python实现)
|
副问题[/!--empirenews.page--]
先容 拥有精采的统计配景对付数据科学家的一般事变也许会大有裨益。每次我们开始试探新的数据集时,我们起首必要举办试探性数据说明(EDA),以相识某些特性的概率漫衍是什么。假如我们可以或许相识数据漫衍中是否存在特定模式,则可以量身定制最得当我们的呆板进修模子。这样,我们将可以或许在更短的时刻内得到更好的功效(镌汰优化步调)。现实上,某些呆板进修模子被计划为在某些漫衍假设下结果最佳。因此,相识我们正在行使哪个概率漫衍可以辅佐我们确定最得当行使哪些模子。 差异范例的数据 每次我们行使数据集时,我们的数据集城市代表总体的样本。然后行使这个样本,我们可以实行相识其概率漫衍,以便我们可以行使它对总体举办猜测。 假设我们要按照一组数据来猜测衡宇的价值,我们可以找到一个包括旧金山全部房价的数据集(我们的样本),举办一些统计说明之后,我们就可以对美国其他任何都市的房价做出相等精确的猜测(我们的总体)。 数据集由两种首要范例的数据构成:数值(譬喻整数,浮点数)和标签(譬喻名字,电脑品牌)。 数值数据还可以分为其他两类:离散和继承。离散数据只能回收某些值(譬喻,学校中的门生人数),而持续数据可以回收任何现实或分数值(譬喻,身高和体重的观念)。 从离散随机变量中,可以计较出概率质量函数,而从持续随机变量中,可以得出概率密度函数。 概率质量函数给出了变量可以便是某个值的概率,概率密度函数的值自己并不是概率,必要在给定范畴内举办积分。 天然界中存在很多差异的概率漫衍,在本文中,我将向各人先容数据科学中最常用的概率漫衍。
在本文中,我将提供有关怎样建设每个差异概率漫衍的代码。起首,让我们导入全部须要的库: import pandas as pd import numpy as np import matplotlib.pyplot as plt import scipy.stats as stats import seaborn as sns 伯努利漫衍 伯努利漫衍是最轻易领略的漫衍之一,可用作导出更伟大漫衍的出发点。这种漫衍只有两个也许的功效,一个简朴的例子就是投掷偏斜/无偏硬币。在此示例中,可以以为功效也许是正面的概率便是p,而对付后面则是(1-p)(包括全部也许功效的互斥变乱的概率总和为1)。 probs = np.array([0.75, 0.25]) face = [0, 1] plt.bar(face, probs) plt.title('Loaded coin Bernoulli Distribution', fontsize=12) plt.ylabel('Probability', fontsize=12) plt.xlabel('Loaded coin Outcome', fontsize=12) axes = plt.gca() axes.set_ylim([0,1])
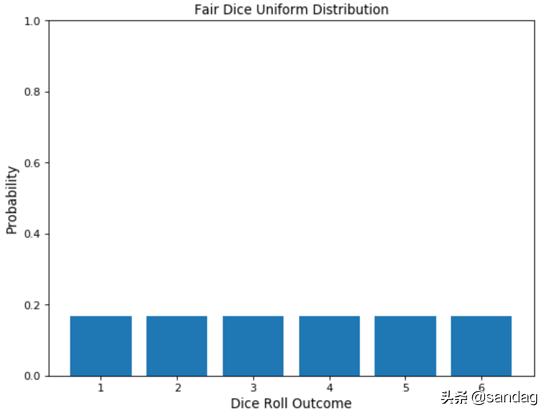
匀称漫衍 匀称漫衍可以很轻易地从伯努利漫衍中得出。在这种环境下,功效的数目也许不受限定,而且全部变乱的产生概率均沟通。譬喻掷骰子,存在多个也许的变乱,每个变乱都有沟通的产生概率。 probs = np.full((6), 1/6) face = [1,2,3,4,5,6] plt.bar(face, probs) plt.ylabel('Probability', fontsize=12) plt.xlabel('Dice Roll Outcome', fontsize=12) plt.title('Fair Dice Uniform Distribution', fontsize=12) axes = plt.gca() axes.set_ylim([0,1])
二项漫衍 二项漫衍被以为是遵循伯努利漫衍的变乱功效的总和。因此,二项漫衍用于二元功效变乱,而且全部后续试验中乐成和失败的概率均沟通。此漫衍回收两个参数作为输入:变乱产生的次数和试验乐成与否的概率。二项式漫衍最简朴的示例就是将有偏/无偏硬币投掷必然次数。 各人可以调查一下差异概率环境下二项漫衍的图形: # pmf(random_variable, number_of_trials, probability) for prob in range(3, 10, 3): x = np.arange(0, 25) binom = stats.binom.pmf(x, 20, 0.1*prob) plt.plot(x, binom, '-o', label="p = {:f}".format(0.1*prob)) plt.xlabel('Random Variable', fontsize=12) plt.ylabel('Probability', fontsize=12) plt.title("Binomial Distribution varying p") (编辑:河北网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |